文件系统及存储系统介绍¶
This article is the lecture note that I've prepared for the Operating System course at Fudan University. It steals a lot from the famous textbool OSTEP, especially the first half, I am very thankful and would credit to the authors of OSTEP who bring the following materials to us. This lecture covers file system, the most intimidating beast in OS, for its intricacy and dedicacy to be persistent, consistent, fault-tolerant and fast. But once we understand the design and development of the file system, we'll see the way to achieve the requirements for file system is not only elegant but also insightful. After the introduction of file system, the other half of this lecture covers a more broad topic of storage system, namely database system. We'll see how database system utilize transaction to enable highly concurrent data access.
文件和目录的组织方式¶
从程序员的角度来看,文件系统展现在我们面前的不过是几个系统调用。这是有道理的,因为读写磁盘显然应该是特权操作,需要交给内核来完成。
概括来看,这些系统调用包括
open: 创建文件描述符¶
int fd = open("/path/to/dir/filename.txt", O_CREAT|O_WRONLY|O_TRUNC, S_IRUSR|S_IWUSR);
上述调用创建了一个文件描述符(file descriptor)。open 的调用方法可以通过 man open 看到,我解释一下这一行调用。第一个参数是
0: stdin, 1: stdout, 2: stderr
// Per-process state
struct proc {
uint sz; // Size of process memory (bytes)
pde_t* pgdir; // Page table
char *kstack; // Bottom of kernel stack for this process
enum procstate state; // Process state
int pid; // Process ID
struct proc *parent; // Parent process
struct trapframe *tf; // Trap frame for current syscall
struct context *context; // swtch() here to run process
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
};
open创建一个文件描述符。文件描述符是 UNIX 系统的特色。在一切皆文件的思想下,进程通过文件描述符来告诉内核
一般来说,文件通过一个树形的结构来索引,叶子节点为文件,中间的节点为目录。但其实目录也是一种文件,同样需要被保存到磁盘上。
有了树形结构,定位文件是通过一串路径字符串完成的。通常,/ 代表根目录,随后 dirname/ 表示下一级的目录,最后的反斜杠后
read/write: 通过文件描述符读写文件¶
char buf[4096];
int num_bytes_read = read(fd, buf, 4096);
int numb_bytes_write = write(fd, buf, strlen(buf));
我们可以用 strace 来查看一个进程的系统调用,故而可以通过 strace cat sample.txt 看到下面结果
(base) ichn@ichn-arch-pc ~ strace cat sample.txt
...
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(0x88, 0x9), ...}) = 0
openat(AT_FDCWD, "sample.txt", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=13, ...}) = 0
fadvise64(3, 0, 0, POSIX_FADV_SEQUENTIAL) = 0
mmap(NULL, 139264, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f72c318a000
read(3, "hello world!\n", 131072) = 13
write(1, "hello world!\n", 13hello world!
) = 13
read(3, "", 131072) = 0
munmap(0x7f72c318a000, 139264) = 0
close(3) = 0
close(1) = 0
close(2) = 0
...
lseek: 非顺序读写¶
off_t lseek(int fildes, off_t offset, int whence);
whence 有几个可能
SEEK_SETSEEK_CURSEEK_END
不过 lseek 并不会真的去做磁盘的寻道,它不过是修改了 file 结构体里表示偏移量的一个变量,只有真的发生读写的时候才会生效。
struct file {
enum { FD_NONE, FD_PIPE, FD_INODE } type;
int ref; // reference count
char readable;
char writable;
struct pipe *pipe;
struct inode *ip;
uint off;
};
我们注意到,之前的 proc 结构体里的
struct file *ofile[NOFILE]; // Open files
是一个指针的数组,主要的目的是,如果一个进程发生 fork,我们需要复制文件描述符,但并不会复制文件。在内核里面有一个管理所有打开的文件的大表,
struct {
struct spinlock lock;
struct file file[NFILE];
} ftable;
进程的文件指针都会指向这里,同时注意到用来做并发控制的锁。
fork/dup: 文件描述符管理¶
如上所述,不信邪可以跑下这个
int main(int argc, char*argv[]) {
int fd = open("file.txt", O_RDONLY);
assert(fd >= 0);
int rc = fork();
if (rc == 0) {
rc = lseek(fd, 10, SEEK_SET);
printf("child: offset %d\n", rc);
} else if (rc > 0) {
(void) wait(NULL);
printf("parent: offset %d\n",(int) lseek(fd, 0, SEEK_CUR));
}
return 0;
}
结果是
prompt> ./fork-seek
child: offset 10
parent: offset 10
prompt>
也就是说子进程改变文件的偏移量,父进程同样会被修改,即他们的文件描述符指向同一个 file 实例。
int ref; // reference count
前述 file 结构体里的 ref 就是用来统计这种复制情况下的索引次数的,只有当 ref = 0 才会从 ftable 里移除。
int new_fd = dup(fd); 用来复制一个文件描述符,得到本质上一样、但不同值的文件描述符。在输出重定向时非常有用,特别是另外一个 dup2(fd, 1);。
可以有以下操作1
ls existing-file non-existing-file > tmp1 2>&1
也可以
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if(fork() == 0) {
close(STDIN); // CHILD CLOSING stdin
dup(p[STDIN]); // copies the fd of read end of pipe into its fd i.e 0 (STDIN)
close(p[STDIN]);
close(p[STDOUT]);
exec("/bin/wc", argv);
} else {
write(p[STDOUT], "hello world\n", 12);
close(p[STDIN]);
close(p[STDOUT]);
}
fsync: 刷缓存到磁盘¶
文件系统通常会缓冲写操作,这会导致系统崩溃时缓存丢失。所以提供 fsync(fd) 系统调用来把脏缓冲写到磁盘里去。
rename: 重命名文件¶
int rename(char* oldname, char* newname);
rename 通常是原子的(atomic)。通过 rename 的原子性,我们可以实现对文件的原子操作,如
int fd = open("foo.txt.tmp", O_WRONLY|O_CREAT|O_TRUNC,S_IRUSR|S_IWUSR);
write(fd, buffer, size); // write out new version of file
fsync(fd);
close(fd);
rename("foo.txt.tmp", "foo.txt");
write 不一定是原子的,如果直接写原来的文件,要是没写完全系统就崩溃了,那么这次写操作就并不满足原子性。
mkdir: 创建文件夹¶
strace mkdir foo
创建一个空的文件夹 foo ,但实际上并不完全空,有 . 和 .. 两个条目。
每个条目包含
struct dirent {
ushort inum;
char name[DIRSIZ];
};
不过是文件名到 inode 编号的一个映射。所有的文件和文件夹,在磁盘上都是一个个的 inode,对于磁盘来说并无区别。
另外一点是权限管理,mkdir 会要求传入一个权限控制的参数,如 0777。解释一下,RWX,所有者、群组、其他人。chmod
rmdir: 删除文件夹¶
只允许删除空文件夹,非空文件夹请先手动删干净。
unlink: 删除文件¶
strace rm tmp.txt 可以看到
unlink("tmp.txt")
文件是写在磁盘上的,其内容和元数据通过 inode 的结构来管理
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
unlink 会做 nlink--,而当 nlink = 0 时这个 inode 才会真的被删除。一般文件 nlink 都是 1,除非
ln: 创建文件链接¶
ln 可以给一个文件创建一个硬链接,在行为上是给原来文件对应的 inode 的 nlink++,并在新文件的目录里新建一个 dirent 指向原来文件的 inode 编号。故而,我们必须保证 nlink = 0 才能删除文件。
从这里可以明白创建硬链接和复制文件的区别。
既然有硬链接,那我们也有软链接。软链接实际上只是做了一个地址翻译,dirent 里面不会指向一个 inode 编号,而是在 name 上做标注。这样原来文件一旦 unlink 就真的删了,所以有悬空软链接的存在的可能(dangling soft link)。
mount: 挂载文件系统¶
把硬件存储器或者其他东西挂载到大的目录空间中来。
万物皆文件(描述符),如 /proc 2。
请见 mount。
一个简单文件系统的实现¶
本节内容主要来自 OSTEP 第 40 章6、第 41 章7、第 42 章8
以 xv6 的 VSFS 为例。
一个文件系统存在目的是保证文件的
- 持久性
- 一致性
持久性是说如何把文件数据写到磁盘上以便以后访问。一致性则是要求无论何时系统崩溃了,数据不会丢失和发生错乱。
关于在磁盘上对数据做持久化,从实现者的角度来看主要关注两点,数据结构和访问方法。
磁盘在文件系统看来不过是一个比较大的线性存储空间,文件系统有责任对这个存储空间进行资源管理,从而完成数据持久化。通常来说空间管理最基本的单元不是字节而是 block,一般大小为 4KB,目的在于与页大小对齐。
之间介绍过了文件的组织方式,但最核心的内容在 inode 这个结构体上。首先 inode 需要被保存在磁盘上,所以我们需要在磁盘上划分空间用来保存 inode;此外 inode 本身不存储数据,只存储其包含的数据的地址,因此需要有空间来存数据。我们还需要对这两者的空间进行规划管理,如果是用 free-list 的方式,我们可以在原址上构造链表,从而不需要额外空间,但通常的做法是用 bitmap,故而还需要两段空间来存 bitmap。最后我们需要存储一些元信息,保存上述空间的规划和根目录对应的 inode 的位置。
综上所述,我们得到下面一张空间安排示意图
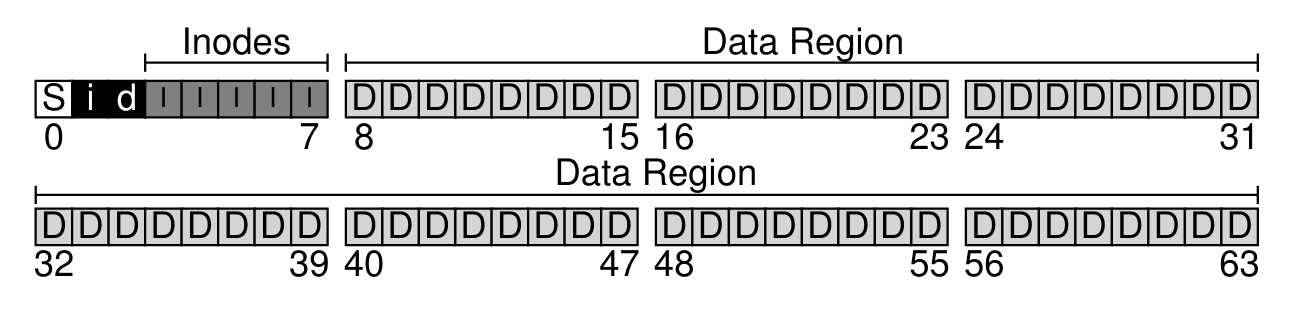
inode 的大小通常为几百字节,所以一个 block 可以存放多个 inode。我们用 inode number 来索引每个 inode。

回顾 xv6 中 inode 结构体的定义
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
的确没有存数据的地方。一个 inode 是如何保存大小千变万化的文件的呢?
Multi-Level Index¶
一个重要的观察是,文件系统中大部分文件都是小文件。

所以 addrs 这个数组前面 12 个位置存的是 direct pointer, 最后一个是 indirect pointer,指向一个全是指针的 block,这个 block 里的指针如果全是 direct pointer,则空间可以扩展到 (12 + 1024) * 4KB;如果还是不够,可以再加一层、再加两层。
另外一种方法是用 extents 来记录,即一个开始地址和长度。
空间管理¶
之前提到的 bitmap 是一个直观的解决方法,另外还有
- Free-list,这是 FAT 文件系统用的方法,FAT 是 file allocation table 的缩写,可谓形象
- 更加复杂的结构,如 XFS 以及 BtrFS 使用的 BTree
总而言之,在空间管理上有很多可以做文章的地方。上述 bitmap 的机制之上也有策略空间,如 ext2/3 会优先找连续的 block 分配给一个 inode。
访问方法¶
如果明白了存储的数据结构,那么文件系统在创建、修改、删除时的行为对于磁盘上的数据的访问方法就比较好懂了,这里带大家过一遍。

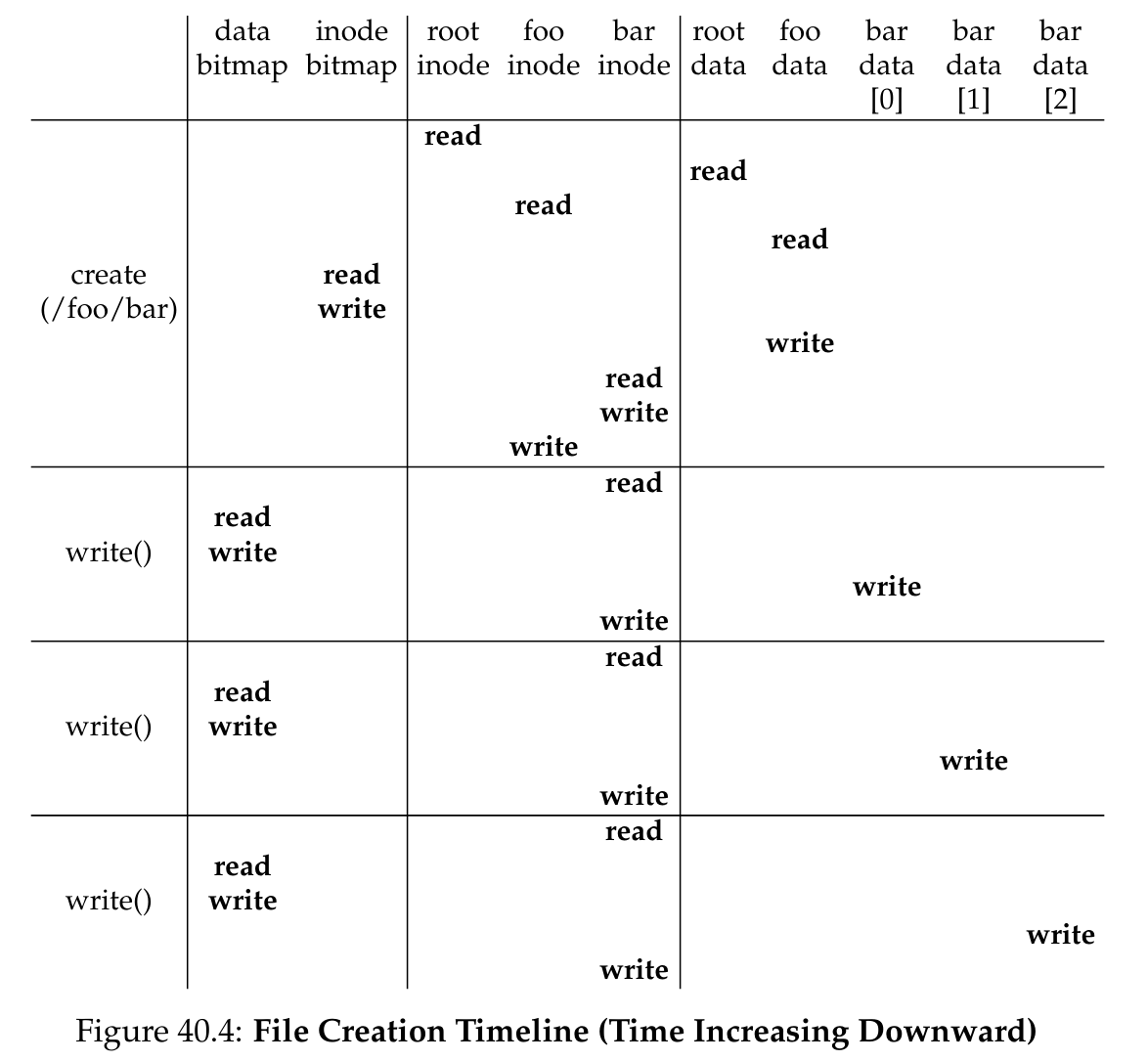
FFS¶
额外提一句,上述的 VSFS 是可用的,但是效率低下。后来有一个改进 FFS,会把磁盘分区,得到多个 cylinder group,尽量在 cylinder group 里面组织文件目录及内部文件,可以收获 locality 加成。Linux 的 ext2 就是实现了这套机制。
缓存和缓冲¶
频繁读比较折腾,所以可以把一部分 inode 缓存在内存里。
频繁写也是,所以可以把写缓冲起来,譬如对 inode bitmap 的修改。
不过缓冲会带来新的问题,若是崩溃会带来数据损失。(虽然即便不缓冲也会有这种可能)。
崩溃一致性¶
如果写一个文件不是原子的,那么有可能在 inode 更新之后还没来得及写数据系统就崩溃了,这样 inode 指向的数据就是错误的。这就带来了一致性的问题。
下面就新建一个文件并追加数据讨论具体的崩溃场景导致的问题。
新建文件需要改 bitmap、inode 和 data block。
- data block 写入了,其他都没完成——没啥大问题,但是写入不成功对用户来说是丢失了数据
- inode 写入了,data block 没来得及——脏数据
- bitmap 更新了但是其他都没——空间泄露
总之要是挂了就很会出问题,必须想办法
- 挂了可以但是必须报错给用户知道,不能不吭声
- 尽量不要造成用户数据丢失
fsck¶
早期解决第一个问题的方式是 fsck。
fsck 是 file system checker 的缩写。在每次挂载文件系统的时候扫盘纠错,譬如检查是否有空间泄露等等。
不过 fsck 需要考虑各种各样的崩溃场景,很难完全,并且需要很多关于实现的具体知识,难以维护。另一个问题则是效率低下。所以后来慢慢就没人用了。
因为我们从数据库领域借用了 WAL 的想法—— write-ahead logging。在文件系统中我们通常称为 journaling,也就是打日志。
第一个问题需要通过事务的原子操作实现,第二个则靠日志恢复,都是通过 WAL 可以实现的。
事务与日志¶
打日志的方法在现代文件系统中已经非常常用,无论是 ext3/4 还是 JFS, XFS, NTFS,这里以 ext3 的实现来介绍一下,因为思想的精髓是一致的。
我们在 super block 和后面的存储区域之前空出一个日志区,对于所有的写操作我们先把操作内容顺序写到日志里。

我们把一次文件的写操作打包成一个事务。我们知道在数据库的语境下事务需要保证 ACID 的特性,我们这里需要的是 A,也就是原子性。

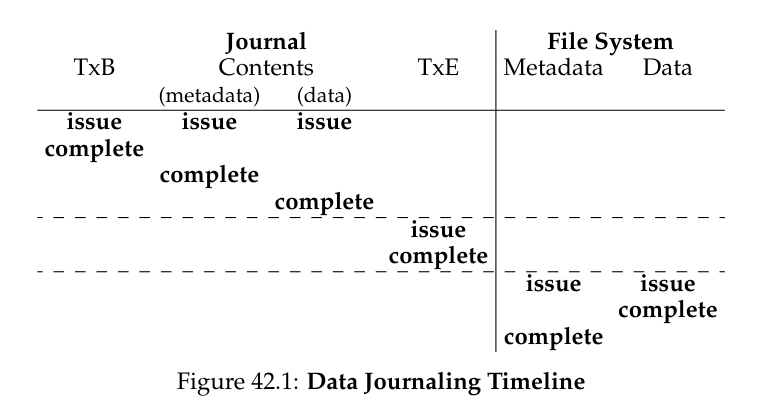
这里 TxB 表示事务的开始,TxE 表示事务的结束,本质上可以通过一个时间戳或者计数器来标记。如果把实际数据也打到日志里,通常称为物理日志,否则称为逻辑日志。
一次事务从 TxB 开始,我们顺序写入各部分的数据,然后确保的确写入之后,再写入 TxE,称为事务提交,然后就可以返回告诉用户写入成功了。到这一步我们就可以保证写入的原子性。如果系统在 TxE 写入之前崩溃了,恢复时 TxB 不会有对应的 TxE 那么这次写入就算作废。同时因为用户没有收到写入成功的信息,理论上并没有损失数据。而一旦写入成功,我们后续会通过打检查点的方式把事务里的数据写入到磁盘数据区域里去,然后从事务日志中删除被检查过的事务。
不过这里面仍然有一些细节问题,第一个是写入的顺序和策略(写屏障与原子写),第二个是只把元数据写入日志,第三个是日志空间管理(循环日志)。
所以一次写入包含
- 写数据
- 元数据写日志
- 提交日志(确保 1 和 2 都已经落盘)
- 检查事务日志
- 释放日志空间
如果真的按上述方式只把元数据写入到日志,并且把目录改动当作元数据时,实际上还有一个关于删除的问题。有两种解决方法,一种是不重用日志中还未写盘的 block,另一种是加 revoke。
下面两个示意图很好地诠释了两种日志的时间线。

Log-structured File System¶
本节内容主要来自 OSTEP 第 43 章5
通过前面的学习我们知道磁盘顺序读写比随机读写要快几个数量级,而前述的文件系统忽略了磁盘读写特性,因此会带来大量的随机读写,虽然 FFS 利用局部性原理适当减轻了随机读写的开销,但仍然不能令人满意。
还有更多的问题有待解决
- 现代计算机的内存容量激增,因此可以缓冲更多的磁盘操作
- FFS 等文件系统本身操作效率就低,写一个文件需要读写 inode, inode bitmap, directory data block, 本身的 data block 以及 data block bitmap
- RAID 不友好,带来 small-write 的问题(或是写放大的问题 write amplification)3
基于上述考量,上个世纪 90 年代初提出了 LFS 4。LFS 的基本思想是,不覆盖数据,只追加。具体来说,磁盘操作会首先在内存中被缓冲,当有一定量时顺序刷入到磁盘中连续的一段空间中。注意一点,顺序写不一定快,只有连续写才快。
缓冲多少数据¶
可以算一算。这样一次写入的数据我们称为一个 segment。
inode 定位¶
VSFS 和 FFS 比较好定位 inode,因为 inode 在磁盘上有固定的存放位置。但这一点在 LFS 中不存在,因为我们要避免覆盖数据,所以 LFS 中 inode 的位置是不固定的。
解决方案来自著名定律:加一层抽象(the solution to all problems in Computer Science is simply a level of indirection)。
inode map: 根据 inode number 索引 inode 的最新的一个版本的位置。

现在问题就变成了如何定位 imap。答案是没有别的办法,只有存在固定的位置上。LFS 会把 imap 的信息存放在一个固定的 checkpoint region 里,不过 LFS 会在运行时把 CR 加载到内存里,修改都在内存中进行,然后定时写盘,这样可以均摊掉读写开销。当然这带来的另一个问题就是没来得及写盘怎么办,我们随后可以看到解决方案。
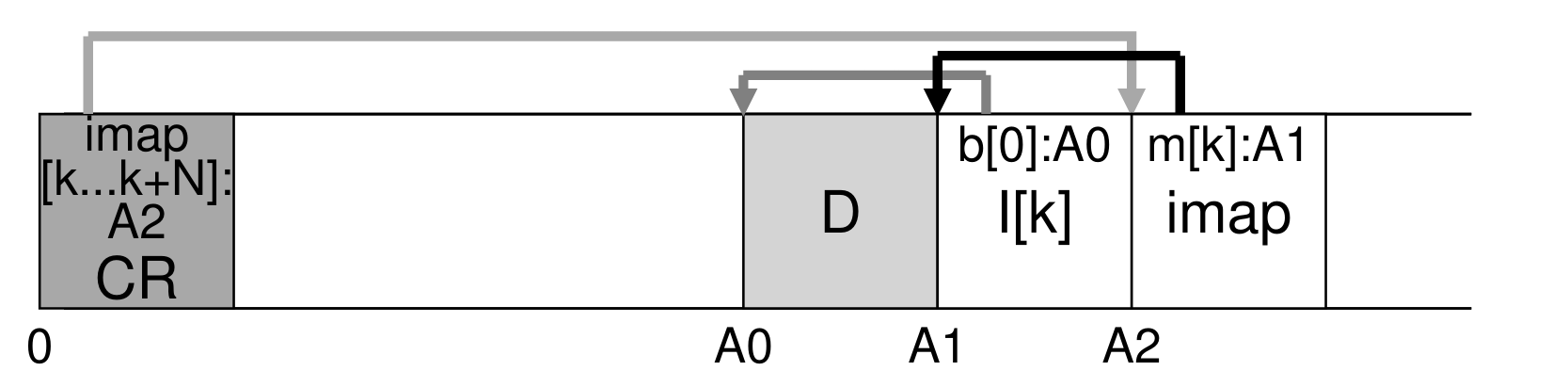
递归更新问题¶
其实 imap 的存在似乎有点多余,为何不直接在 CR 里存 inode 的位置呢?本质的原因在于文件目录修改时会导致递归更新。
因为文件目录也是文件的一种,修改文件目录会在文件目录的数据段做修改。假设有一个文件被修改了,则 LFS 会创建一个新的 inode 和 imap。由于文件的 inode 位置改变了,则其所在的目录的条目也要做修改,基于 LFS 的不修改只追加的基本思想,文件目录的更新也会导致新的目录 inode 的创建,由此需要不断地往目录上层做修改,造成递归更新的巨大开销。
好在我们有 imap。本来文件目录存储的就是从文件名到 inode number 的映射,这样查找文件的时候都会从 CR 里的 imap 找 inode 的地址,这样一来只需要修改 CR 里将对应 inode number 的 imap 修改为新的 imap 即可。
垃圾回收¶
因为 LFS 只追加不修改,如果一个文件的某个 block 被追加的 block 完全覆盖了,原来的 block 就过时了,成为了垃圾数据,应当被回收。
(也不尽然,可以保留,做成带版本的文件系统。)
垃圾回收(garbage collection, GC)是一个非常重要的概念,只要有资源管理的场合就不得不考虑。我们面临的第一个问题是,如何确定垃圾数据。第二个问题是,我们需要保证空间的连续性,因为我们要求连续写。
存活判断¶

其实也比较简单。LFS 在每个 segment 之前添加一个 segment summary block,里面记录了这个 segment 内每个 data block 的
- 所属的 inode number(属于哪个文件)
- 关于所属 inode 的 block 编号(是这个文件的第几个 block)
读 SSB, 然后对于每个 block 读 inode 和 inode 对应的 block 的地址,比较是否和当前 block 相同,如果一样则说明存活,否则代表有更新的 block 替代了当前 block。
(N, T) = SegmentSummary[A];
inode = Read(imap[N]);
if (inode[T] == A)
// block D is alive
else
// block D is garbage
有一个更有效的方法是在 imap 和 SSB 上加上一个版本号,可以避免读 inode。
数据压缩(compaction)¶
因为我们需要连续的空间,我们不能瞎搞,做法是数据压缩。每次读 M 段数据,剔除里面的垃圾数据,然后重新组织写入新的 N 段数据,保证 N < M。
回收时机与对象¶
另外一个问题是,什么时候做数据压缩以及对哪些段做压缩。区别于之前的机制问题,我们现在考虑的是策略。
时机:周期性或者容量阈值;对象:冷热段,先清冷段。并不完善。
一致性保证¶
两个 CR,磁盘头尾各一个 CR,交换写入,保证 CR 写入的原子性。在写 CR 的时候,先写入一个时间戳,然后写入 imap 数据,最后再写一次时间戳。这样,如果在写 imap 数据的过程中系统崩溃了,这个 CR 的时间戳就不一致。LFS 在挂载的时候会采用最近的时间戳一致的 CR 读入内存,因此下次挂载的时候会用另外一个 CR 的数据。如果只是如此,我们可能会损失 30 秒的写入数据。
实际上 LFS 也有 log 机制,把每次操作都顺序写在 CR 里,这样我们读入一个 CR 的同时也会读入日志,之后我们可以根据日志尽可能地往前滚动来恢复数据。
评述¶
LFS 这种只追加不修改的机制并不是首创(叫做 copy on write),70 年代末在数据库领域就提出了类似的思想 shadow paging。但是这种做法实在是高妙,为后来的很多系统做了启发。91 年的 LFS 论文发表在 SOSP,至今有高达两千多的引用量。即便在 SSD 开始涌现的今天,copy on write 的机制仍然是最具竞争力的选择。
SSD¶
打算简单介绍一下。
SSD 的存储结构和磁盘完全不一样,不存在机械的部分。这让 SSD 在随机访问的性能上有了长足的进步,不过仍然与顺序读写有一定差距。SSD 利用一块块的闪存来存放数据,其基本抽象是 block 和 page。block 一般大小为 128KB ~ 2MB, page 的大小为 1KB ~ 8KB。
SSD 的读取比较简单,但写入需要对一整块 block 做擦除,然后每一个 page 只能写一次,想重写需要再擦除该页所属的 block。擦除整个 block 不仅效率低,而且每个块有擦除寿命限制,因此我们需要设计一层中间层来对闪存的 block 做抽象,把擦除均匀摊布到所有 block 上,避免对一个 block 的重复擦除。
这层中间层叫做 flash translation layer(FTL),目的是把逻辑块地址翻译成物理块地址,通常通过 log-structured 的形式来实现。
所以 FTL 需要实现翻译的映射,而这个映射本身也是需要做持久化的。具体的讨论比较复杂,可以参考 OSTEP10。
这些都是通过 FTL 做的抽象,在外界看来这块 SSD 和一般的磁盘没有什么两样的,所以有一个说法是每个 SSD 里面都跑着一个 LFS9,也是有道理的。
Storage System¶
Log-structured 和日志的思想影响深远,后来启发的 Log-structured Merge Tree(LSM-Tree)也成为数据库领域的统治性的索引存储结构。在讨论完文件系统之后,我们不妨看一看数据存储系统。
在数据库领域之中,一个非常重要的问题是如何保存索引,换句话说如何做有序的 KV 存储。从基本的数据库课程上我们可以学到 BTree,也就是拍扁的平衡树——充分利用 block 并减少读磁盘取次数。 但一般来说 BTree 的修改是原地的(in place),会带来大量的随机访问降低效率,在大量写、少量读的场景下,BTree 会比较糟糕。 然而在数据库的场景下,写的量往往远大于读,特别是对于 KV 存储来说,因此我们有必要对这类场景做一些优化。
这里我们介绍的就是一个在目前数据库领域应用非常广泛的存储结构 LSM Tree,也是受 log-structured 启发的。
LSM Tree (log-structured merge tree)¶
LSM tree 是存储索引的数据结构。
其他参考
- TxFS: Leveraging File-System Crash Consistencyto Provide ACID Transactions
- http://www.eecs.berkeley.edu/Pubs/TechRpts/1992/CSD-92-696.pdf
- https://draveness.me/bigtable-leveldb
- http://www.benstopford.com/2015/02/14/log-structured-merge-trees/
-
https://stackoverflow.com/questions/11635219/dup2-dup-why-would-i-need-to-duplicate-a-file-descriptor ↩
-
https://en.wikipedia.org/wiki/Procfs ↩
-
https://en.wikipedia.org/wiki/Standard_RAID_levels ↩
-
https://web.stanford.edu/~ouster/cgi-bin/papers/lfs.pdf ↩
-
http://pages.cs.wisc.edu/~remzi/OSTEP/file-lfs.pdf ↩
-
http://pages.cs.wisc.edu/~remzi/OSTEP/file-implementation.pdf ↩
-
http://pages.cs.wisc.edu/~remzi/OSTEP/file-ffs.pdf ↩
-
http://pages.cs.wisc.edu/~remzi/OSTEP/file-journaling.pdf ↩
-
http://pages.cs.wisc.edu/~remzi/OSTEP/file-ssd.pdf ↩